Self-Hosted RAG Chatbot for AKFA Holding
We developed a custom RAG chatbot for AKFA Holding's trilingual corporate website that answers visitor questions using only indexed site content.

Client & Context
AKFA Holding is one of the largest conglomerates in Central Asia. It spans construction, appliances, tourism, healthcare, education.
The holding includes 40+ companies, which makes the website rich in information but difficult to navigate quickly.
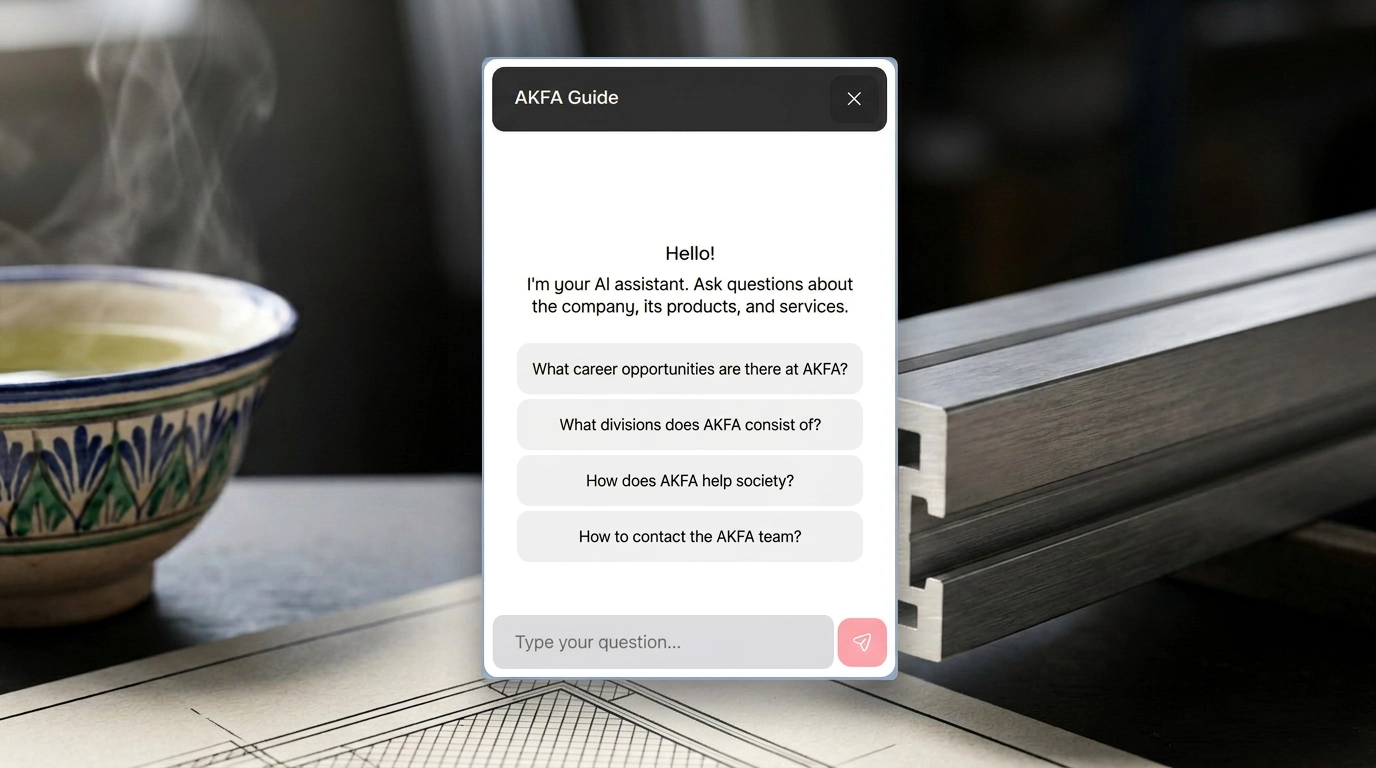
To help visitors easily find relevant companies, services, and information without wasting time, AKFA needed a reliable chatbot, especially in Uzbek.
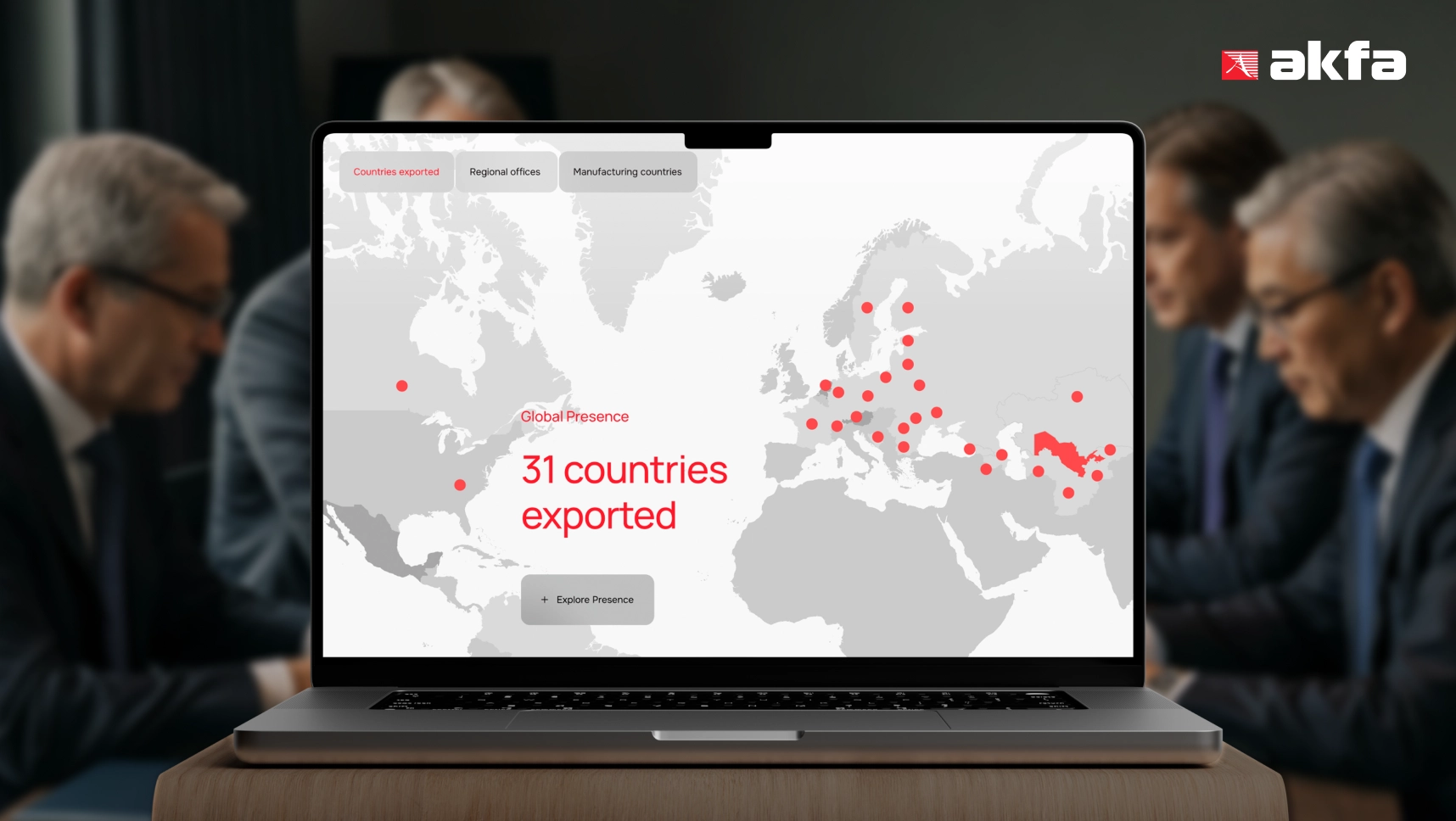
AKFA’s global structure needs more than menu navigation. The chatbot helps users quickly reach the right part of a large corporate site.
Goals
- 1Ground every answer in published website content and uploaded internal documents.
- 2Let content managers update content, system prompts, and error messages in three languages without developers.
- 3Find relevant answers by meaning, not just exact keyword matches, using RAG architecture.
Challenges & How We Overpowered Them
Inside the AKFA Holding Chatbot
Why We Built It Custom
PostgreSQL was already in the stack — enabling pgvector gave us a vector index without a separate service.
Filament holds ~20 model types with multilingual fields. SaaS bots don't speak this schema and tend to underperform on Uzbek.
Page-aware retrieval, source citations, and refusal policy are architectural choices.
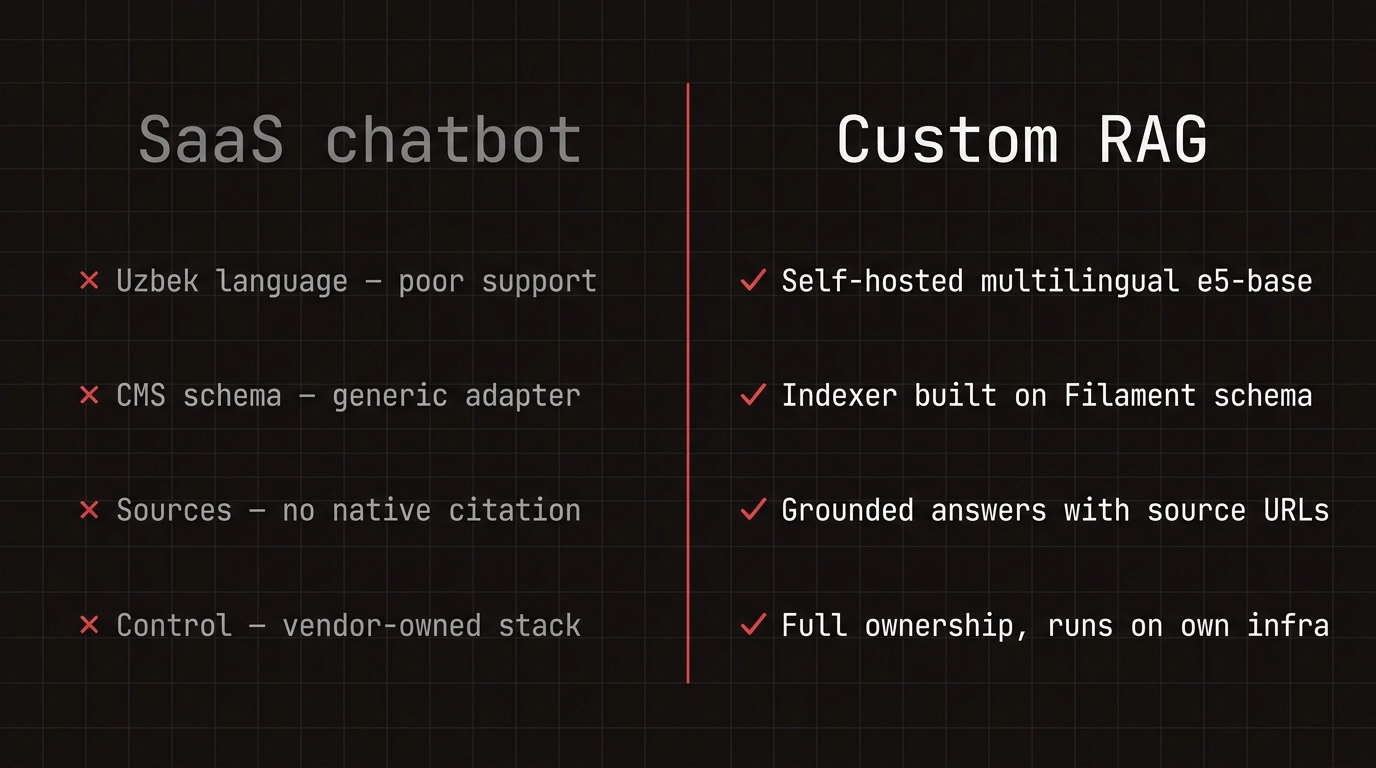
Custom RAG solved what SaaS chatbots could not.
Turning a Complex CMS into Chatbot Knowledge
A custom indexer reads CMS content through an internal API. It splits content into chunks and stores 768-dimensional vector embeddings in PostgreSQL with the pgvector extension.
Content managers can also upload supplementary TXT documents — regulations, FAQs, briefs — and the bot indexes them the same way.
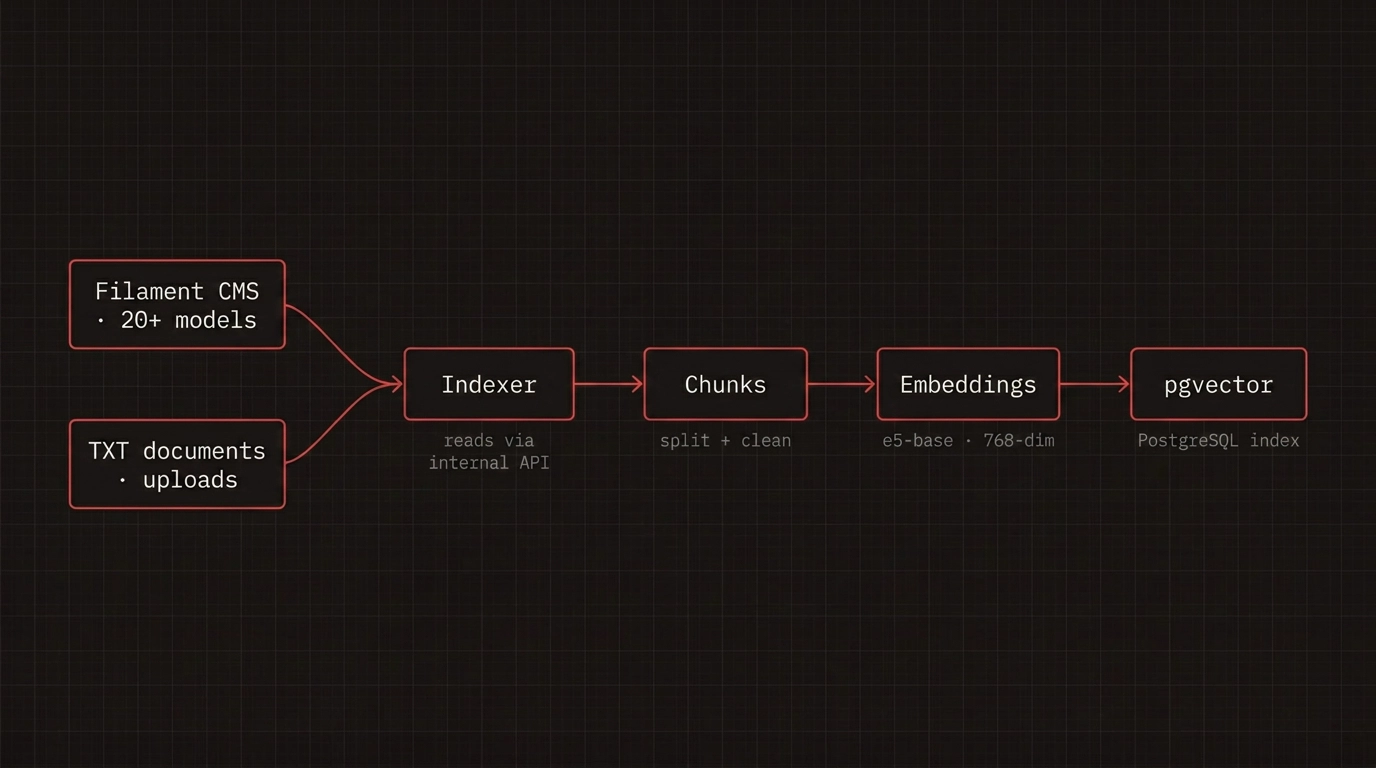
The indexer turns CMS content into chatbot knowledge. Pages and TXT files are cleaned, chunked, embedded, and stored in pgvector.
AI Architecture That Can Evolve Without Rebuilding Everything
We split the AI stack by how often each layer changes.
Embeddings are the foundation — switching them means full reindexing. We self-host intfloat/multilingual-e5-base for native languages coverage.
LLM generation is the experimentation zone. We route through OpenRouter and swap models with a config change.
The Bot Checks the Current Page First
Every request includes the visitor's current page URL. The bot first searches for relevant chunks on that specific page.
With three or more quality matches, it answers from the page. With fewer, it expands to the full site index — page context is a priority with graceful fallback.
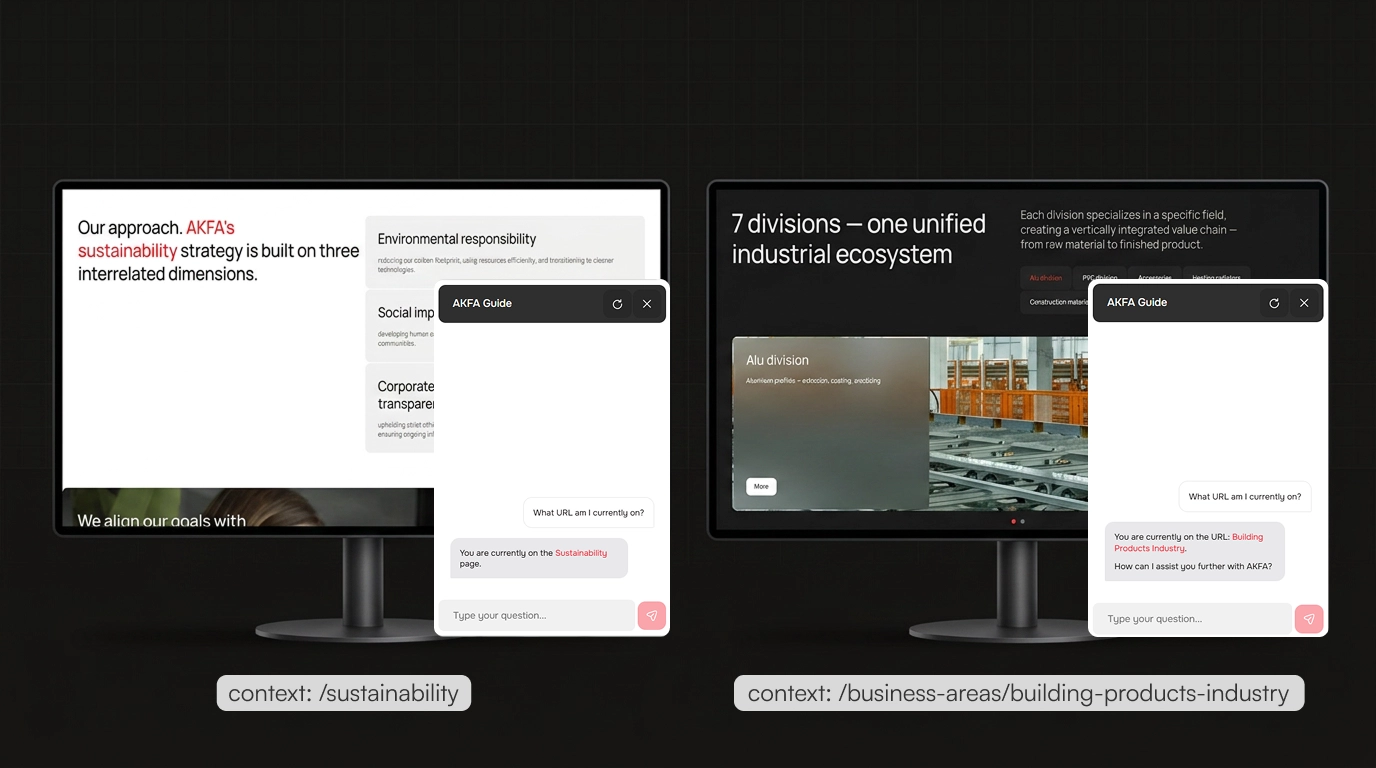
Page context makes answers more precise. The bot checks the current URL first, then expands search to the full site.
Answers Based Only on Verified Content
The LLM generates phrasing. Indexed content provides the facts.
When retrieval finds nothing relevant, the bot says so plainly. Every answer ships with a deduplicated list of source URLs, enforced at the architecture level.

Every answer stays traceable. Source URLs show where the chatbot found the information.
Follow-Up Questions That Still Make Sense
Short follow-ups get rewritten into standalone queries before retrieval. "When was it founded?" becomes "When was AKFA Holding founded?"
Chat history travels with each request from the client. The RAG service stays stateless — easier to scale, better for privacy.
Fresh Answers Within 10 Minutes of Every CMS Update
Every 10 minutes, the indexer checks the CMS for pages with an updated timestamp.
Only changed content gets reindexed. Unchanged chunks reuse existing embeddings, saving compute.
Deleted or unpublished pages disappear from the index automatically on the next cycle.
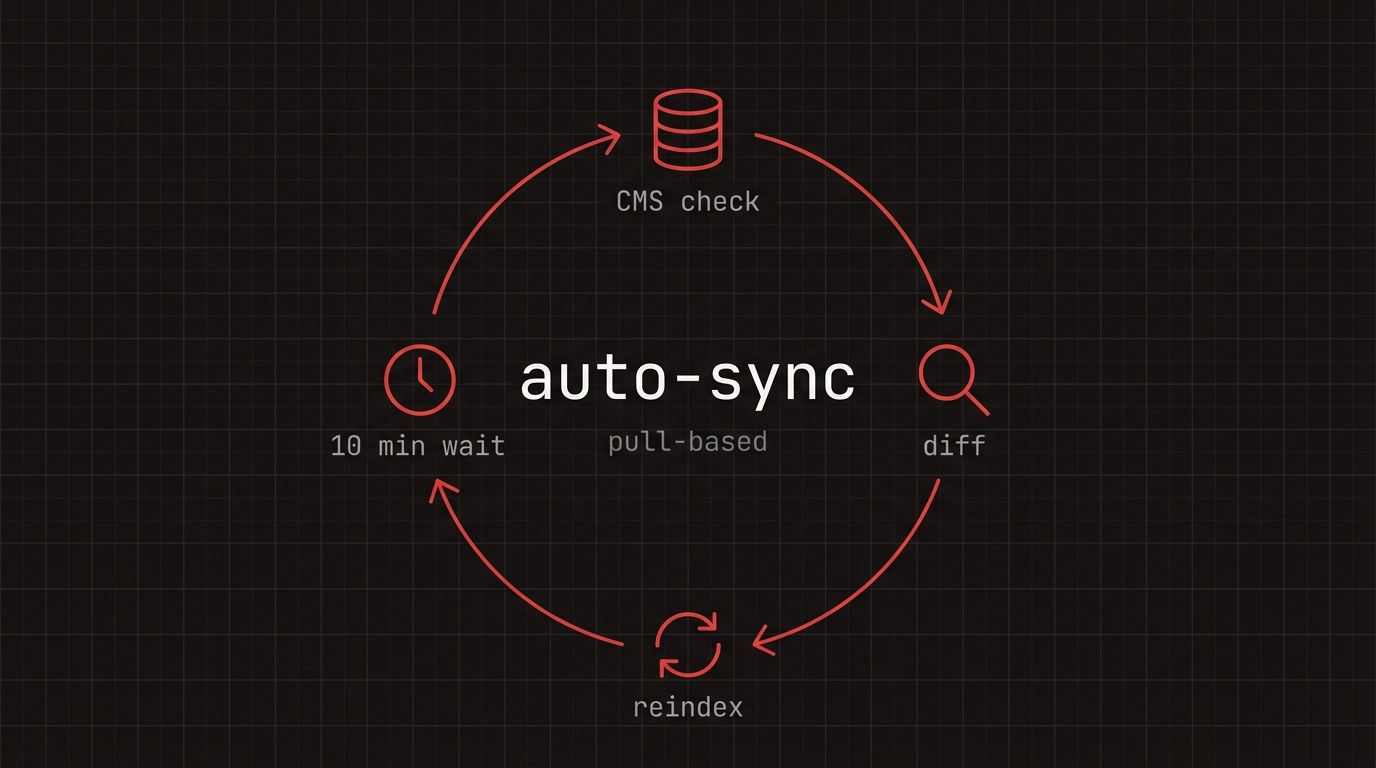
Knowledge stays fresh automatically. Every 10 minutes, the system checks CMS updates and reindexes only changed content.
Compliance & Security
Results
The chatbot launched on AKFA Holding's corporate website. It answers visitor questions in three languages, cites sources in every response, and refreshes its knowledge within 10 minutes of any content update in the CMS.
See also

E‑commerce Website with 5700+ SKUs for a UAE-based Company

Designing an AI-Powered Journaling App for Daily Reflection and Personal Insights

Scientific Trial PDFs Extraction
How to Fit 40+ Companies In One Corporate Website
Self-Hosted RAG Chatbot for AKFA Holding

SMM Content Automation with AI

17–22 PM Hours Saved per Project With AI Workflows

From a Month of Production to a 2-Minute Draft: AI Case Study Pipeline