Scientific Trial PDFs Extraction Cut from 2 Hours to 15 Minutes at >90% Accuracy
We developed an AI assistant for a top-10 crop science multinational that extracts structured PECO fields from scientific trial PDFs with human-in-the-loop review.

Client & Context
A top-10 global crop science company. Agronomy and regulatory teams run systematic reviews of trial literature.
Each review uses the PECO framework — Population, Exposure, Comparator, Outcome. Analysts pulled these fields manually from PDFs.
One article took two hours. The team handles hundreds of articles a year.

Goals
- 1Cut analyst time per article without losing accuracy.
- 2Hit ≥85% extraction accuracy on a held-out test set.
- 3Ship a deployment plan including on-prem.
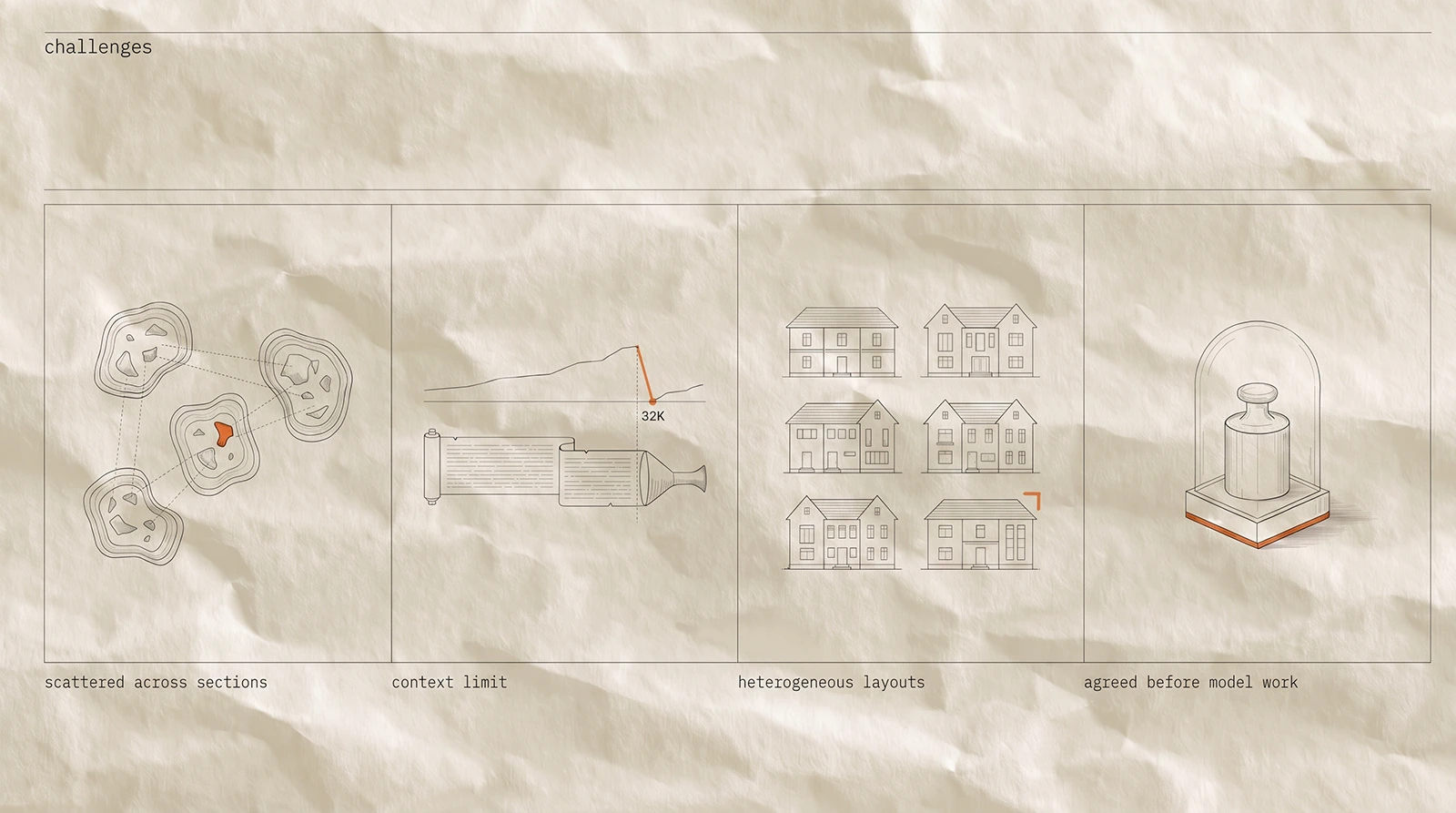
Challenges & How We Overpowered Them
From Schema Definition to Production-Ready Pipeline
Schema definition
We formalized the extraction schema as extended PECO — four standard fields plus study-design and regional-context attributes.
Defining the schema surfaced disagreements between research leads. Resolving them before any model work started was the highest-leverage hour of the engagement.
Quality criteria, evaluation scheme, and working assumptions were locked in week one.

Retrieval and extraction pipeline
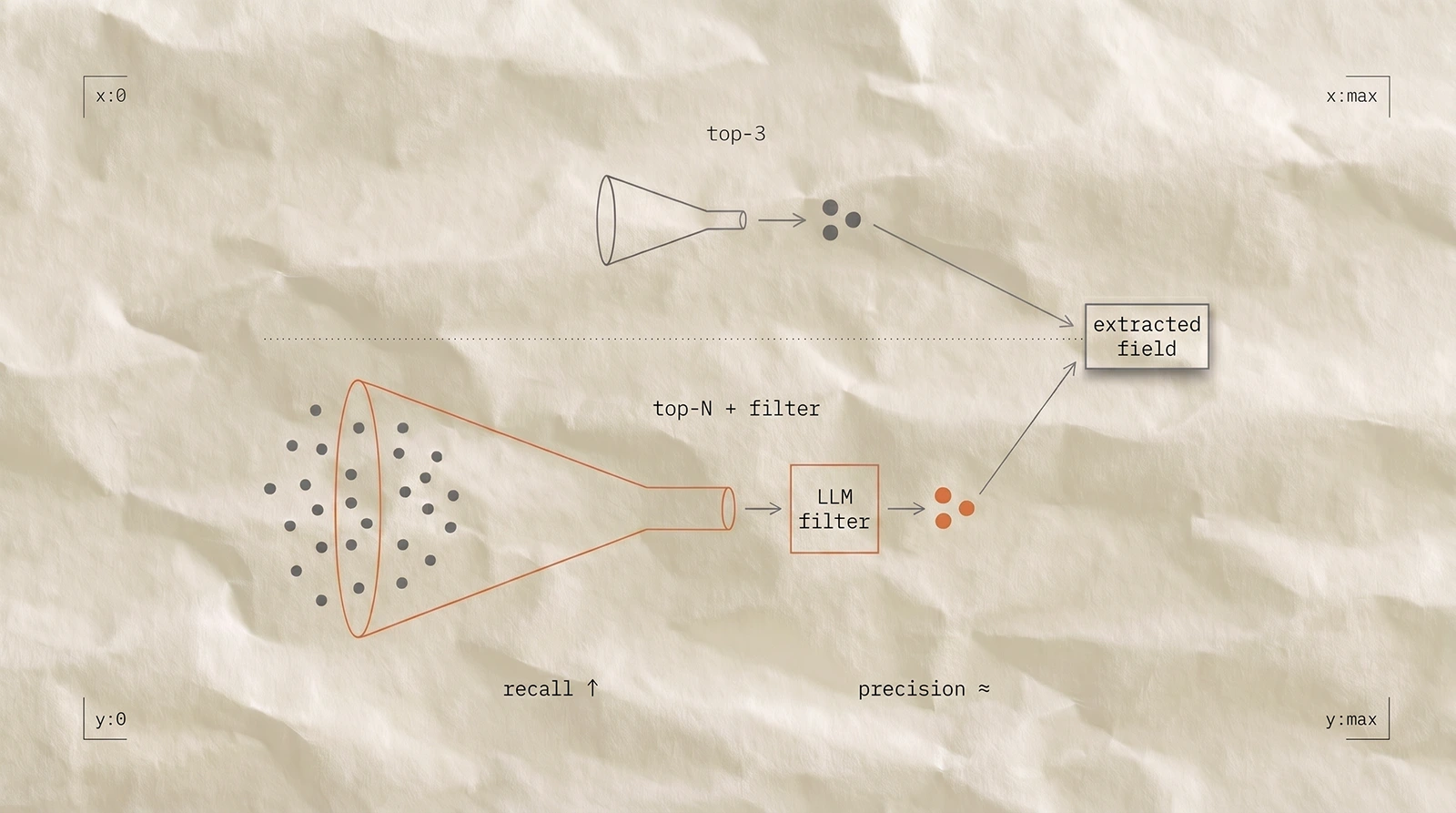
The decisive move was widening retrieval from top-3 passages to a broader candidate set, then letting the LLM filter.
Recall on per-field extraction rose into the 90s with no observable precision loss on the validation set.
Retrieval ran on SciBERT-class scientific embeddings adapted to the in-domain corpus. A GPT-class model handled field-level extraction.
PDF parsing with traceability
Fragment coordinates carried end-to-end through the pipeline. Every extracted fact traces back to its source span.
Text embedded inside images and figures was handled with coordinate awareness. This outperformed classic OCR and text-layer parsers on this corpus.
Heterogeneous article layouts were the second engineering hurdle. Several samples per format meaningfully improved robustness on edge layouts.

Analyst review interface
The web UI is a fix-and-confirm review surface. Each screen puts the analyst between an extracted fact and its source span.
SSO-friendly auth. Drag-and-drop PDF intake.
The results screen shows each extracted field next to the passage it came from. Quick-edit affordances make corrections take seconds.

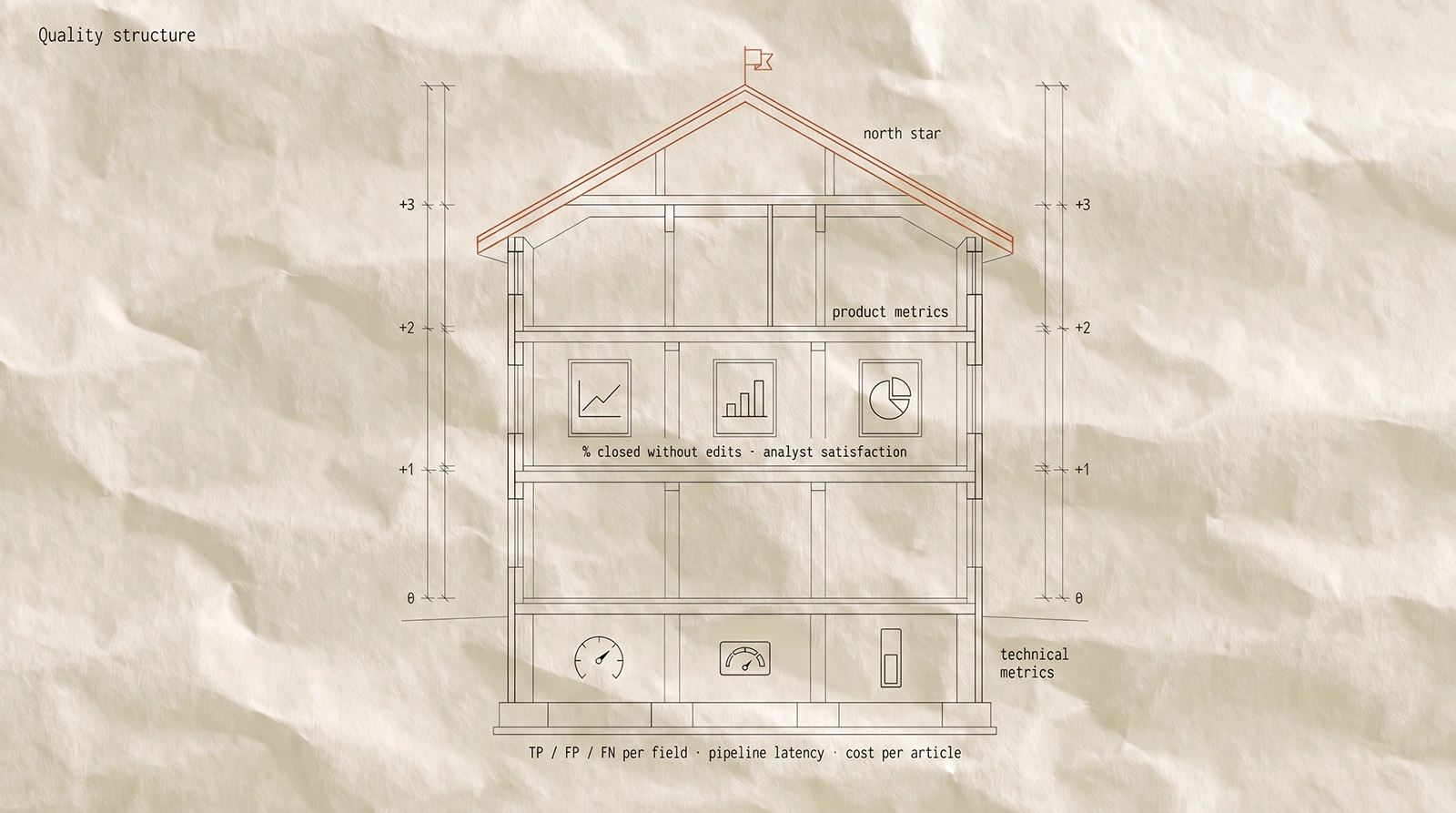
Metrics and production memo
We tracked a three-tier metric pyramid. North Star — end-to-end review time at required accuracy.
Product metrics covered time per article, share of articles closed without analyst edits, analyst satisfaction. Technical metrics covered TP / FP / FN per field, pipeline latency, infra cost per article.
Compliance & Security
Results
- 1Time per article: 2 hours → 15 minutes with human review.
- 2Extraction accuracy: >90% on the typical corpus.
- 3Annual savings: ~875 hours at 10 reviews × 50 articles (≈$48K at $55/hour fully loaded).
- 4Pilot delivered in 7 weeks from kickoff to working pipeline.
See also

Designing an AI-Powered Journaling App for Daily Reflection and Personal Insights
Self-Hosted RAG Chatbot for AKFA Holding

SMM Content Automation with AI

17–22 PM Hours Saved per Project With AI Workflows

From a Month of Production to a 2-Minute Draft: AI Case Study Pipeline